
Blog > Digitizing the Photothek’s Card Index: Insights into the Project’s Development
Digitizing the Photothek’s Card Index: Insights into the Project’s Development
June 24th, 2025
Introduction
Since 1902, the KHI Photothek’s card index has systematically documented photographic acquisition until the transfer to electronic records in 1993. Organized into three distinct catalogues (artists, topography, and iconography) this analogue index continues to serve as an essential resource for research, reflecting archival practices at the Photothek.
In collaboration with the Digital Humanities Lab, the Photothek is working to transform the card index into a structured, searchable digital resource. The initiative aims not only to preserve the content of each card but also to maintain the original organizational framework. The project is structured around three primary objectives:
-
Digitize and Transcribe:
All analogue cards are converted into machine-readable records through an AI-driven transcription pipeline. This system processes both handwritten and typed entries, including archival symbols and shorthands, and outputs structured text. Transcriptions with low confidence scores are flagged for manual verification to ensure accurate capture of metadata.
-
Enhance Access
The project aims to enable full-text search and advanced metadata queries across the entire collection, allowing researchers to filter results by specific fields and discover photographs, including those not yet digitized, within the Photothek’s holdings. Also research on canon formation, provenance, the mobility of images will be enhanced.
-
Integrate and Preserve
The integration of transcribed data into the Photothek database is planned to enhance existing records and add new entries, supporting the database’s ongoing expansion and enrichment.
Digitizing and annotating each card ensures these archival records are preserved and accessible in a single, searchable catalogue that connects the analogue and digital collections. For more details, visit the project page.
On May 29, 2025, we shared our preliminary findings and methodology at the European University Institute’s event “Photography and Archives: Discovery, Technology and Innovation” presenting our pilot scanning test, AI-assisted transcription process, and plans to expand the project.
The Card Catalogue
Established in 1902, the Photothek’s card index consist of three indices organized by artist name, geographic location, and iconographic theme. These indices encompass all sections of the Photothek’s holdings, including paintings, sculpture, applied arts, drawings, and prints.
In total, 553 262 cards describe 495 397 photographs spread across seven collections: Architecture (37 126 cards), Sculpture (46 761), Paintings (136 510), Drawings (80 965), Graphic art (13 000), Arts & crafts (20 240) and Iconography (218 660). Each paper card records essential metadata such as creator, date, location, subject, and other relevant details pertaining to the photograph.

© Bärbel Reinhard 2024
Card Structure and Metadata Fields

The card catalogue consists of two types of cards: separator cards and index cards. Separator cards define categories and can be nested to create classification hierarchies. Index cards are linked to one or more photographs within the Photothek’s collection and provide detailed information about each photograph and its subject.
While index cards generally follow a consistent layout, variations exist due to differences in data availability and evolving cataloguing practices over time. A recent study identified approximately fifty-three distinct layout templates, each featuring minor variations.
Each index card contains key information about the photograph and its depicted object. Typical fields include:
- The photograph’s inventory number, often marked with a red dot to indicate cataloguing status
- The photograph’s location within the archive
- The object’s title, artist, and date of creation
- The geographic location associated with the object
-
Information specific to the photograph, such as the photographer’s name and negative number
Additionally, some index cards feature handwritten annotations or corrections; for example, if a photograph is missing, this is noted directly on the corresponding card.
Digitization
In September 2024, a targeted scanning test was conducted on a selected subset of the card index, encompassing approximately 1500 cards. This initiative served two primary purposes:
-
Evaluate Scanning Quality
To assess the technical feasibility of digitizing the entire collection while maintaining high image quality and legibility.
-
Test Transcription Techniques
To evaluate various AI-based OCR models and prompt strategies in order to determine the most effective approach for accurate and reliable data extraction.
The results of this test are currently under review to guide the scaling of the project to include the entire catalogue.
As the project moves forward, the evaluation of scanning techniques remains a critical step. Identifying the most suitable hardware and workflows will ensure both efficiency and long-term preservation quality for the full collection.
AI-Aided Automatic Transcription
Prompt Engineering
- Instructing the model to recognize and categorize metadata fields despite minor variations in card layouts
- Accurately transcribing handwritten annotations and corrections, some of which are difficult to read even for human reviewers
- Correctly identifying categories and subcategories, a task complicated by inconsistencies in how these are visually indicated across cards.
Several iterations of prompt design were tested to address these challenges. Each version was evaluated for its ability to handle field recognition, layout variability, and metadata assignment. Feedback from these tests informed progressive refinements.
The final prompt guides the model through a multi-step process: first, distinguishing separator cards from index cards; second, constructing a hierarchical folder structure based on identified categories; and finally, extracting all relevant data from index cards and mapping each element to the corresponding metadata field. This prompt includes comprehensive descriptions of all known field types, layout variations, and exceptional cases. The central challenge lay in achieving a balance between clarity and completeness to reduce the risk of transcription errors.Cards Transcription Platform
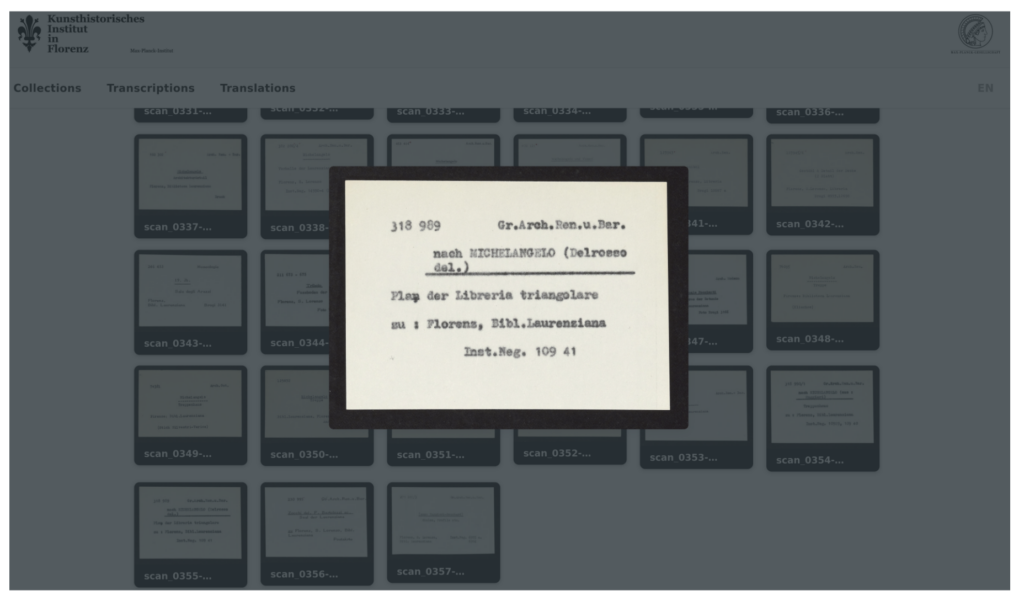
A primary goal is to train the AI to distinguish between category (separator) cards and index cards. As soon as a category is identified, the system creates a folder structure that mirrors the original card catalogue’s hierarchy. After each transcription run, index cards are automatically sorted into these folders based on the category cards, preserving the archival organization in the digital environment. Each card links to its own metadata page, which displays the transcription output—including recognized fields and any flagged uncertainties that require human review.
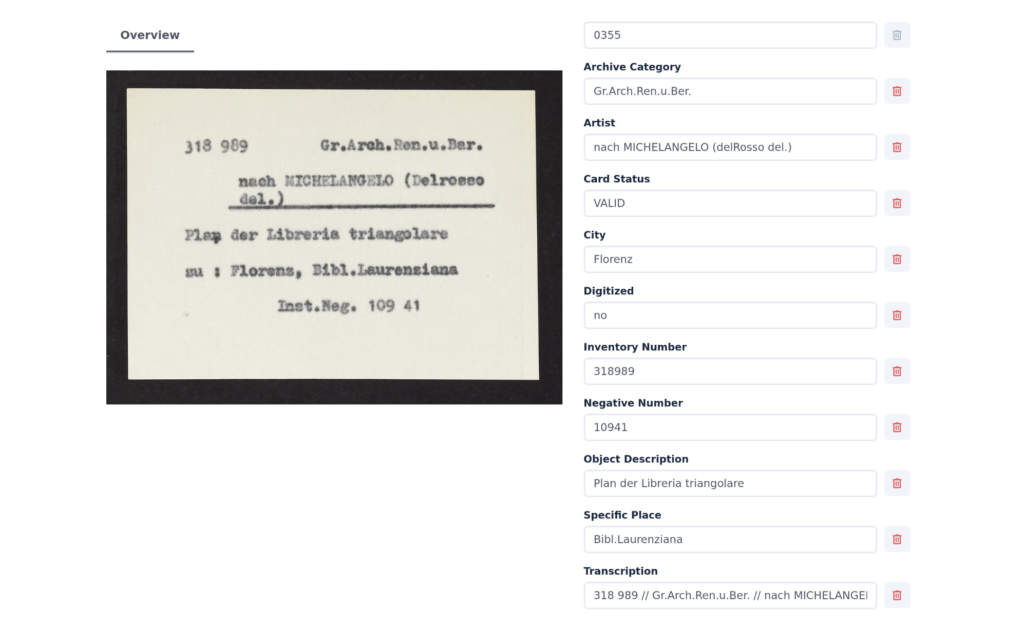
Evaluating Transcriptions
-
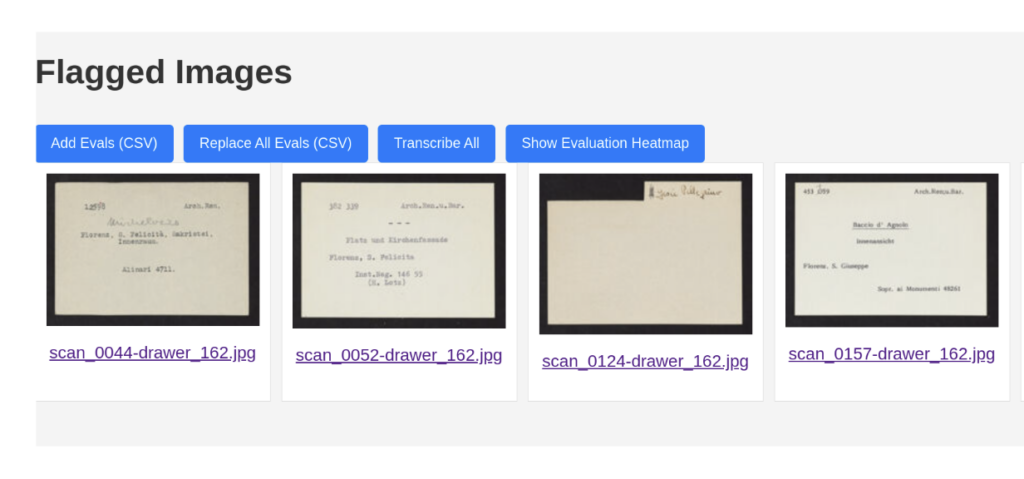
Flagged Images Gallery
The platform displays all “flagged” cards, containing transcription errors or uncertain fields, as a series of thumbnail previews. Users can click on any thumbnail to visualize a detailed comparison of model outputs versus user corrections, helping to quickly identify problematic scans or fields.
-
Detailed Comparison View
This view presents a side-by-side layout showing:
- The original scanned card image
- The “ground truth” or user-corrected transcription
- Transcriptions generated by each selected LLM and prompt
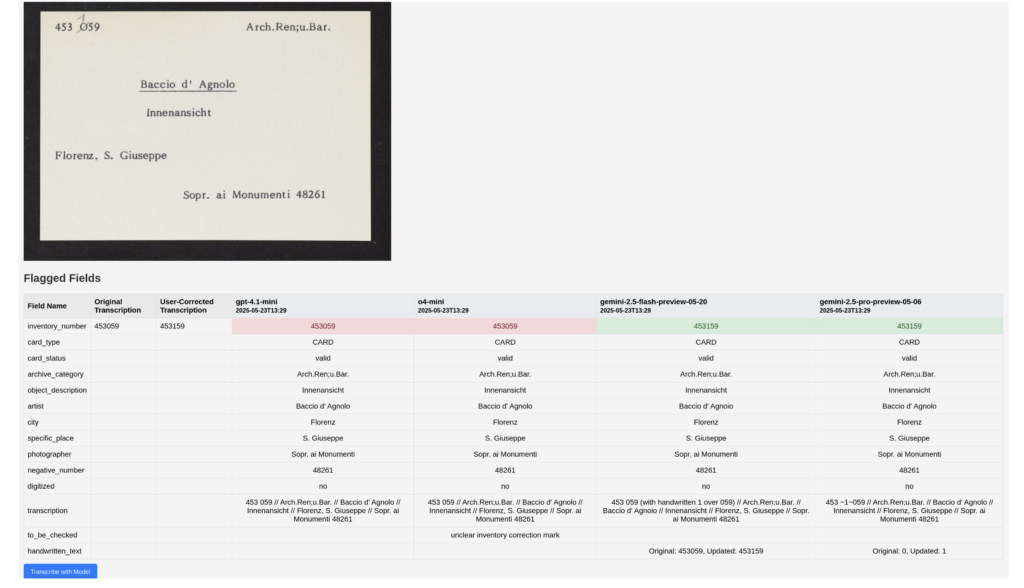
-
Evaluation Heatmap
A heatmap summarizes how each LLM and prompt combination performed on every metadata field. Cells are color-coded—green for exact matches, yellow for partial matches, and red for mismatches—enabling quick identification of which fields and prompts produce consistent errors or require further refinement. The summary interface helps quickly reveal recurring transcription issues across multiple cards.
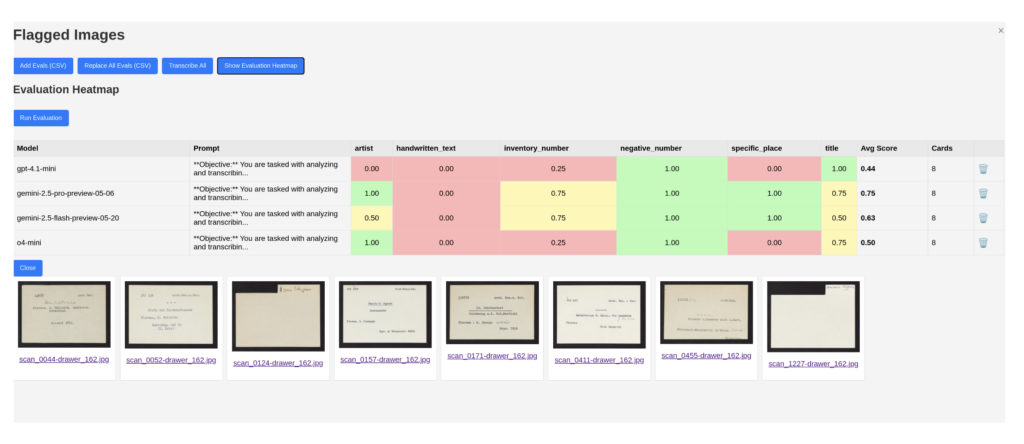
Conclusion
This digitization initiative transforms the Photothek’s historical card index into a structured, machine-readable resource, preserving its archival logic while enhancing accessibility. By combining AI-driven transcription with systematic evaluation tools, the project establishes a scalable workflow for converting complex analogue data into interoperable digital formats. The ongoing refinement of prompts, model comparisons, and human-in-the-loop verification ensures the metadata remains accurate and contextually reliable. Future phases will focus on expanding coverage, improving automation for handwritten material, and integrating the outputs into the main collections database.
